
Image Credit: Quora
by Ryan P. Burge, Eastern Illinois University
One of the most exciting developments in statistical analysis is the rapid expansion in the use of machine learning. Put succinctly, machine learning is the ability for scientists to teach algorithms how to complete a task, usually by giving it some general guidance and then letting it review large datasets to learn what factors are causing it to guess incorrectly.
For instance, when you open your Snapchat and apply a filter to your face, a machine learning algorithm is guessing where your facial features are and updating the filter in real time to match the movement of your eyes and nose. Facebook’s facial recognition software now correctly identifies 98% of faces, which is better than the FBI can do. Google has been using a machine learning program for years in order to teach its self-driving cars how to react to scenarios that they have not encountered before.
But can those algorithms be applicable to the world of religion and politics? I wanted to see if I could teach an algorithm to correctly guess whether a survey respondent is an evangelical Christian. In order to do that I used the 2000-2014 versions of the General Social Survey. The definition of evangelical that I used was the one most widely accepted by social scientists: reltrad, which is a shorthand for “religious tradition.” This typology places individuals into seven categories based on what type of religious service they attend. Here’s how they break down in the sample.
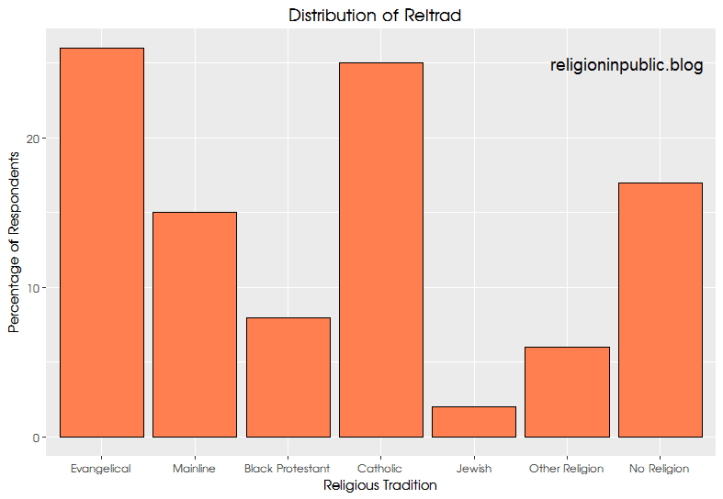
The largest group are evangelicals, making up about 25% of the overall sample. I want to train my algorithm to make a simple decision, either a respondent is an evangelical or they are not an evangelical. To do this, I offered up a number of features to help the program understand what characteristics are the most predictive of evangelical affiliation. I chose things like: how often they attend church, do they believe that state sponsored prayer should be allowed in public school, do they believe in a literal bible, their gender, their race, the amount of education they have received, their political ideology, and their age.
The type of machine learning I used was called a decision tree. It essentially creates a number of branches based on the features that it is given and ends up putting each respondent in a bucket at the end which is the algorithm’s best guess as to whether the individual was evangelical. Here’s what my best tree looked like.

Here’s how to interpret the graphic. Each box represents a “yes” or “no” decision. Looking at the very first branch, the program decided that how often someone attended church is the most important factor. If a respondent attended less than once a month, the best guess was they were not an evangelical. In the bottom left box you can see two things.
- 54% of the sample doesn’t attend church once a month.
- 86% of those individuals are NOT evangelicals, while 14% are evangelicals.
If you could ask a person one question to help you guess if they were evangelical or not it would be: how often do you attend church? If they said they attend less than once a month you would guess that they are not evangelical and be right 86% of the time.
If you look at the right hand side of the decision tree you can see that the algorithm tried to make more nuanced guesses by refining the religious attendance measure and then moved on to partisan identity at the second stage. The algorithm reduced the question to: “Are you a Republican?” and if so, that person was classified as an evangelical as well. (The “repubid” variable was coded 0 as Strong Democrat, 3 as Independent, and 6 as Strong Republican.) Bucket #12 was the second largest portion of the sample (17%). It was arrived at by filtering those who did not attend church multiple times a week and those who espoused a political ideology that was left of center. That bucket was 77% accurate. Bucket #26 held 14% of the sample. If one didn’t attend church multiple times a week, had a political ideology that was NOT left of center, and did not believe in a literal bible they were classified as not evangelical. This prediction was 67% accurate.
I have tried to feature engineer this a little bit and the best I can do is correctly predict about 80% of individuals.
Here’s the takeaway. The two defining characteristics of evangelicalism are: high church attendance and Republican affiliation. It’s pretty amazing to see an algorithm arrive at that conclusion, matching Strato Patrikios’ conclusion that the evangelical and Republican identities are “fused.”
The Github repository for this post is here. Feel free to fork it and try to make the prediction even better.
Ryan P. Burge teaches at Eastern Illinois University in Charleston, Illinois. He can be contacted via Twitter or his personal website.

[…] this post was a discussion some of my close family and friends have had over Trump, a recent post on algorithms, and another post on the use of language. Burge, in his article on algorithms, found that there was […]
LikeLike
[…] in Public has a pithy and readable description of how to build an evangelical-identifying algorithm. What’s interesting, beyond the machine’s success at prediction, is how the author […]
LikeLike
[…] a previous post, I used a machine learning algorithm to try to correctly guess whether members of a random sample […]
LikeLike
[…] religious groups. We have published A LOT about evangelical Christians. Sometimes we debate whether that’s too much. Then we try to balance that out and write a post about Muslims, or Jews, or […]
LikeLike